
MatAi | AI赋能材料知识管理,从查资料到会思考的变革
一、研究背景
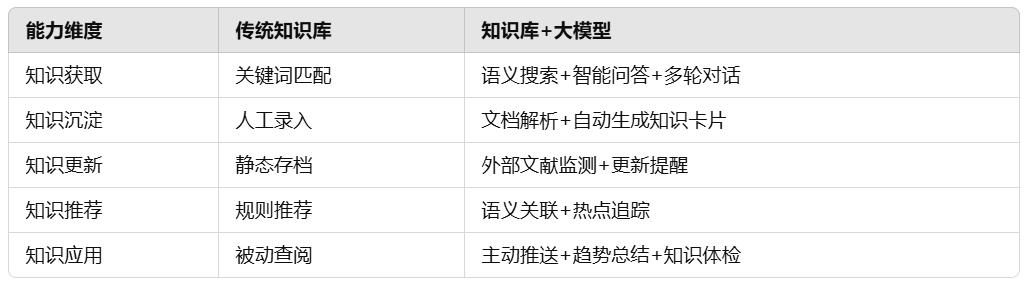
随着人工智能与自然语言处理(NLP)技术的飞速发展,传统企业知识管理模式正面临深刻变革。企业知识库作为组织信息资产的核心载体,长期以来承担着文档存储、分类整理和关键词检索等基础功能。然而,随着企业业务场景日益复杂,知识库的“静态存储、人工维护”模式已逐渐无法满足现代企业对高效获取知识和知识智能应用的更高要求。尤其在材料研发、装备制造、生命科学等技术密集型行业,知识库承载的往往是高度专业化、深度碎片化的科学知识。传统知识库面临以下显著挑战:
- 知识内容形式复杂,涵盖文献、实验数据、标准规范、专利、图表、代码等多种类型;
- 专业术语、表述逻辑与日常语言存在巨大差异,传统关键词搜索效果欠佳;
- 新知识更新速度快,人工维护难以及时追踪;
- 知识之间的关联逻辑复杂,缺乏系统化的知识网络构建能力;
- 研发人员往往需要在海量异构数据中“手工挖矿”,严重影响研发效率。
在此背景下,大语言模型(LLM)的引入,为企业知识库的智能化升级提供了前所未有的技术机遇。然而目前的大语言模型在科学文献理解方面仍存在明显局限,主要表现为缺乏针对特定学科的深度知识和对科学任务的适应性不足。此外,这些模型大多仅针对通用任务进行训练,而科学文献理解需要处理更为专业和复杂的任务,如表格数据提取和专有词汇的解析等,现有模型在这些领域的表现常常不理想。因此,针对材料行业的科研人员,我们提供了材料领域的大模型与知识库结合的应用案例。该案例将知识库与大模型结合起来,能够深度理解自然语言查询,并结合上下文与已有知识生成高质量答案,帮助科研人员快速定位和提取文献关键信息,提升科研效率。
二、知识库与大模型训练框架
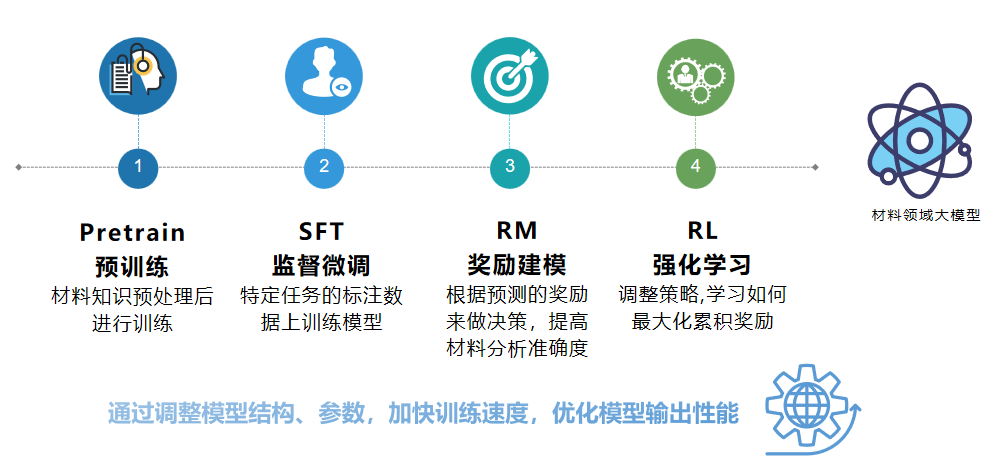
针对上述问题,在训练时,材料大模型的构建采用类似GPT的架构,基于仅由解码器组成的Transformer结构,并通过自回归方式构建语言模型。这种设计结合了自注意力机制,使模型能够有效捕捉长距离的上下文信息,从而增强了模型的表示能力和理解能力。通过这种架构,模型在处理材料领域的文献数据时能够更准确地捕捉语义关系,提升对复杂专业知识的理解和生成能力。
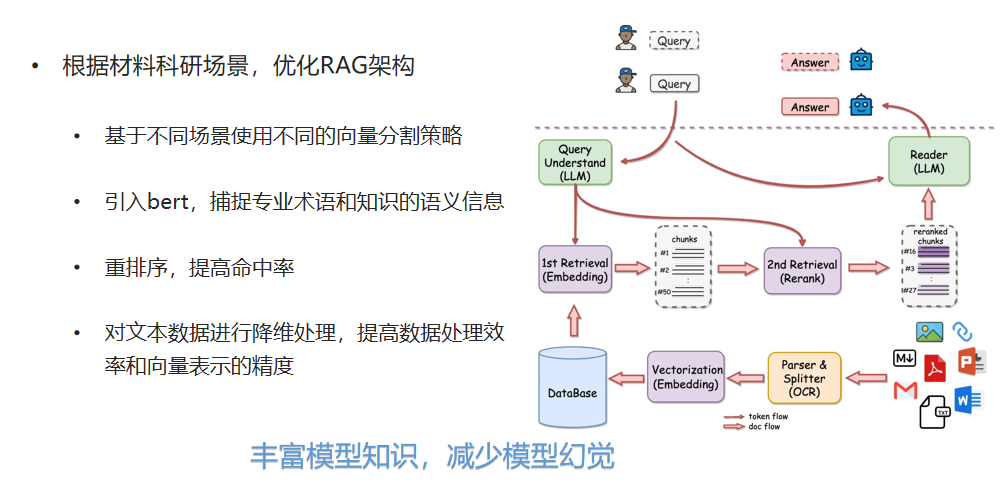
在构建过程中,我们给大模型注入了专业科学知识库,利用上亿篇高质量的材料领域专业文献进行预训练,让模型具备更丰富的科学知识,在此基础上持续进行科学微调,提升模型在处理科学文献阅读任务时的理解力与执行能力。
三、材料大模型应用案例
01领域知识智能推荐
基于用户需求,结合大模型的语义理解能力,从海量科学文献中筛选出相关度高的研究成果,支持精确检索与快速定位。
02数据智能提取与检查
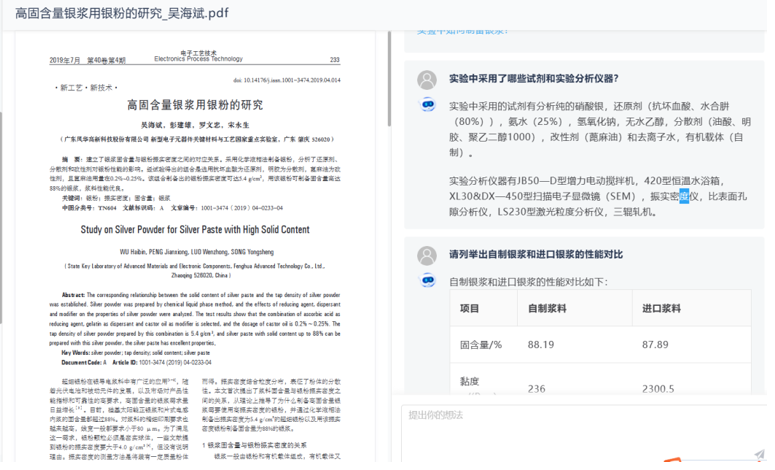
能够从文献中高效提取结构化和非结构化数据,包括表格、图表及文本中的关键指标和信息,同时通过一致性验证和规范化处理,确保数据的准确性和标准化。借助语义解析技术,大模型能够深入理解文献内容,挖掘隐含关系和逻辑,识别潜在错误并提供纠正建议。
03智能翻译
在自动翻译与总结方面表现出卓越能力,能够精准翻译专业术语。

04智能阅读与总结
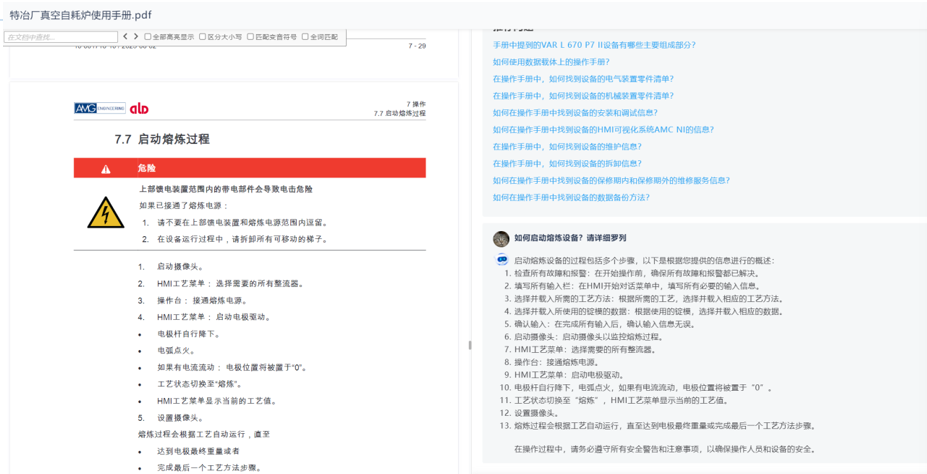
手册数据通常成百上千页,频繁查找需要耗费大量时间,智能阅读可以帮我们通读手册内容,快速获取关键信息,显著提升阅读效率。
- 咨询热线:028-68214380
- 咨询电话:15108472585
- 咨询邮箱:contact@mat.ai
