
MatAi | AI+材料科学:大模型如何加速新材料研发与应用
一、材料大模型研究背景
1. 材料研发面临的挑战
随着新材料研发的深入推进,材料科学领域正面临一系列挑战:
l 信息爆炸与检索难度增加:海量科研文献、专利、实验数据的快速增长,使得研究人员难以快速定位有价值的信息。
l 跨学科知识融合难:材料科学涉及化学、物理、计算机科学、工程等多个学科,传统的数据分析工具难以实现跨领域的信息整合。
l 材料性能预测的复杂性:新材料的发现和优化需要处理大量实验数据和模拟计算,现有方法耗时长、成本高,难以高效筛选和优化材料配方。
2. 大语言模型(LLM)在材料科学中的潜力
目前大语言模型(Large Language Model, LLM)在自然语言处理(NLP)和知识提取方面取得了突破。通过深度学习和语义理解技术,大模型能够:
- 快速筛选、整理和理解材料文献,帮助研究人员高效获取关键信息。
- 分析材料实验数据,自动识别数据中的模式、趋势,并进行预测分析。
- 辅助材料设计与性能优化,基于已有数据预测材料性质,加速材料研发。
然而,目前的通用大语言模型在科学文献理解方面仍存在明显局限,主要表现为缺乏针对特定学科的深度知识和对科学任务的适应性不足。尽管大型语言模型在自然语言处理领域取得了显著进展,但它们未能有效应对科学文献中的复杂领域概念。此外,这些模型大多仅针对通用任务进行训练,而科学文献理解需要处理更为专业和复杂的任务,如表格数据提取和专有词汇的解析等,现有模型在这些领域的表现常常不理想。因此,针对材料行业的科研人员,我们提供了材料领域的大模型应用案例。该案例涵盖常见科研阅读需求,帮助科研人员快速定位和提取文献关键信息,提升科研效率。
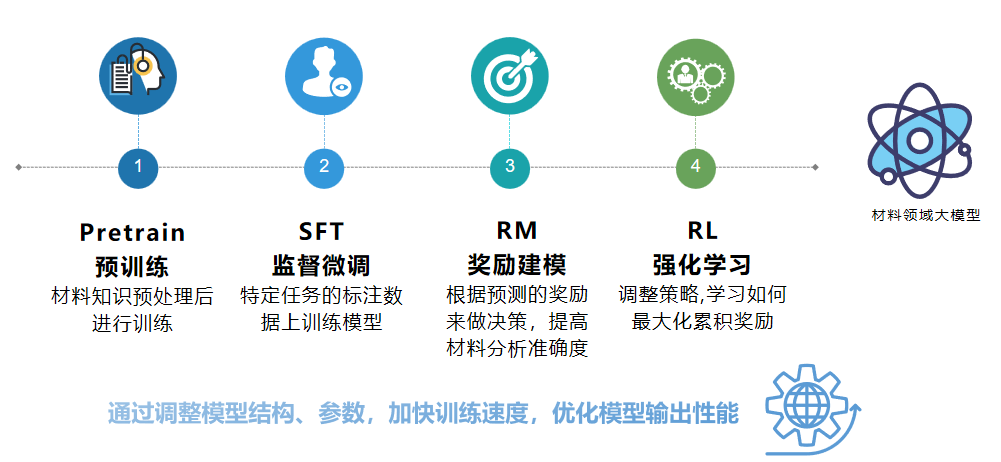
二、材料大模型训练框架
材料大模型的构建采用类似GPT的架构,基于Transformer解码器(Decoder-Only),并通过自回归方式训练。这一架构能够:
- 捕捉长距离上下文信息,增强模型在处理复杂材料知识时的理解能力。
- 高效学习材料领域专业术语,提升对材料科学文献和数据的解析能力。
- 生成科学合理的材料配方建议,支持智能材料研发。
为了确保模型具备深厚的材料科学知识,我们利用多源高质量数据进行训练,包括:
- 学术论文数据:来自高影响力期刊的论文,涵盖新材料发现、性能分析、实验方法等内容。
- 专利数据库:材料科学相关专利数据,用于识别行业前沿技术与创新趋势。
- 实验数据与计算模拟数据:包含材料结构、性能测试、分子动力学模拟、第一性原理计算(DFT)等数据,支持材料预测与优化。
- 行业标准与技术规范:收录 ASTM、ISO、GB 等标准,确保模型在实际工程应用中的可行性。
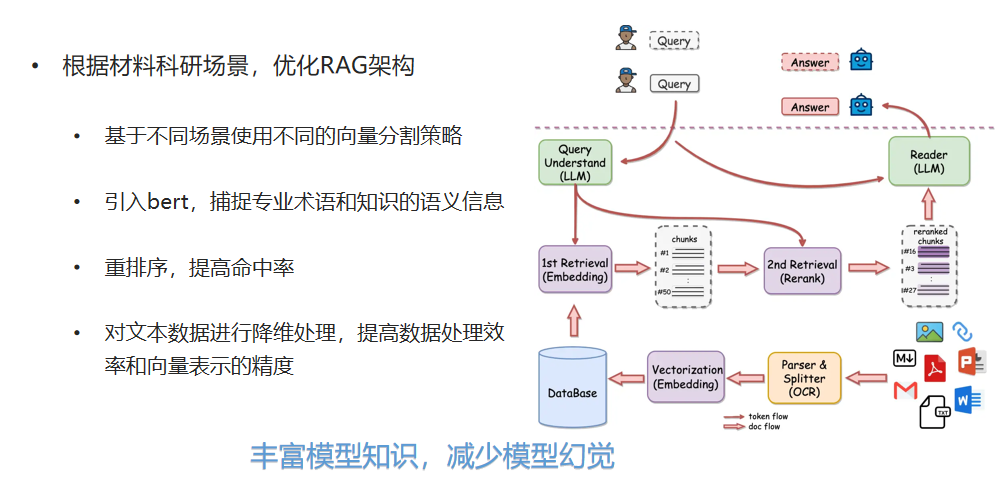
三、材料大模型应用案例
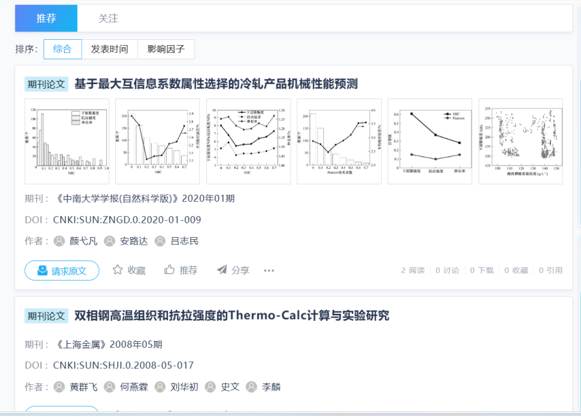
01领域知识推荐
新材料开发需要查阅大量科研文献,但传统检索方法耗时较长,且难以准确获取相关信息。
�大模型能力:
- 精准检索:基于用户输入的研究方向,智能推荐相关度最高的文献。
- 知识摘要:快速提取论文中的关键结论,帮助研发人员高效阅读。
- 趋势分析:跟踪特定材料或技术的发展趋势,辅助研发决策。
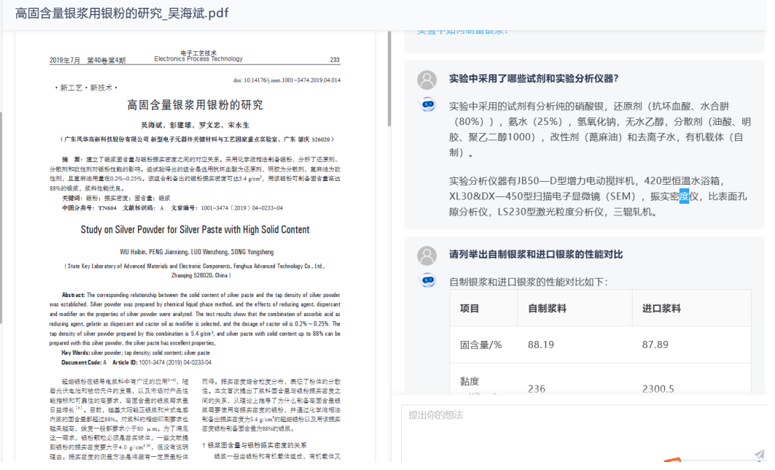
02数据提取与检查
材料研发需要处理大量实验数据,包括成分、性能参数、工艺条件等,数据格式多样且难以统一。
�大模型能力:
- 自动提取表格数据:从论文、专利、技术手册中精准提取材料成分、性能指标。
- 一致性验证:对比多个来源的数据,识别潜在错误或异常值。
- 数据标准化:自动转换单位、匹配行业标准,提高数据质量。
03智能翻译与总结
科研团队需要参考多语言文献,但专业术语翻译往往不准确,影响理解。
� 大模型能力:
- 精准翻译:针对材料专业术语进行优化,提高翻译质量。
- 智能摘要:根据用户需求,提供简明摘要、详细摘要等多种阅读模式。

04研发智能助理
研发团队在实验过程中需要随时查询材料配方、工艺参数,但传统查询方式效率低。
�大模型能力:
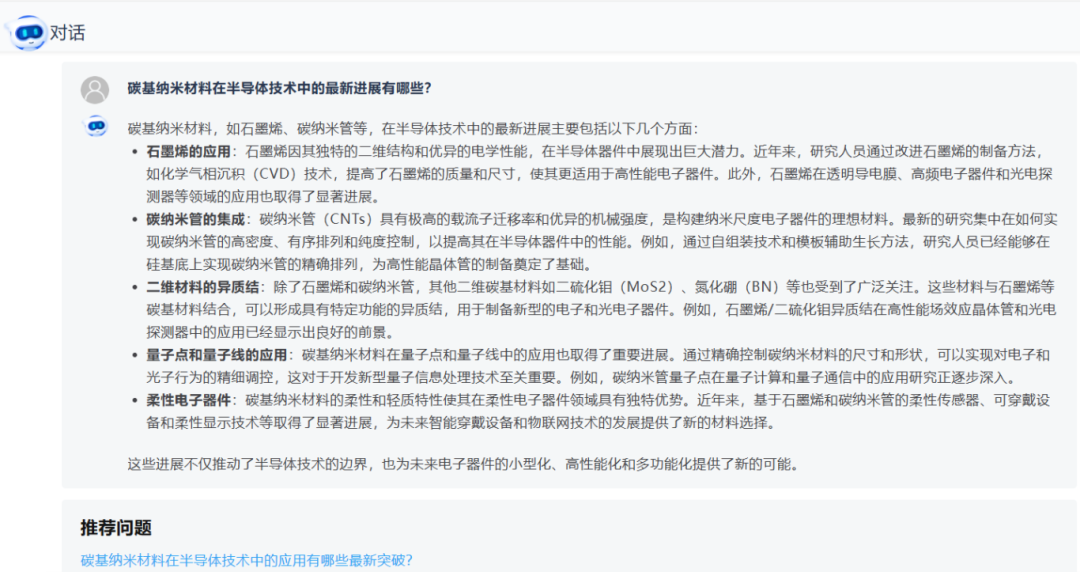
- 实时问答:研发人员可以向模型提问,如“如何提高某种聚合物的耐热性?”大模型能提供基于最新研究的答案。
- 实验方案优化:结合已有数据,提出合理的实验方案,提高实验成功率。
- 咨询热线:028-68214380
- 咨询电话:15108472585
- 咨询邮箱:contact@mat.ai
